The recent blog post, Access Relational Databases Anywhere with StreamSets Cloud and SSH Tunnel, presented an overview of StreamSets Cloud’s SSH tunnel feature. In this article, aimed at IT professionals who might have to configure an SSH tunnel, I’ll look a little more deeply into SSH tunneling, and explain how I configured my home router and SSH server to allow StreamSets Cloud access to PostgreSQL running on my laptop on my home network.
Scope of SSH Tunnel in StreamSets Cloud
From its initial release, StreamSets Cloud has been able to directly access cloud-based relational database services such as Amazon RDS, Google Cloud SQL and Azure’s databases. From the January 13, 2020 release, StreamSets Cloud has also been able to securely access on-premise databases via an SSH tunnel.
SSH tunneling is supported by all of the relational database stages currently available in StreamSets Cloud:
- MySQL Binary Log
- MySQL Multitable Consumer
- MySQL Query Consumer
- MySQL Producer
- Oracle CDC Client
- Oracle Multitable Consumer
- Oracle Query Consumer
- Oracle Producer
- PostgreSQL Multitable Consumer
- PostgreSQL Query Consumer
- PostgreSQL Producer
- SQL Server Multitable Consumer
- SQL Server Query Consumer
- SQL Server Producer
We’ll start with a quick look at how an SSH tunnel actually works, move on to cover SSH tunnel configuration in StreamSets Cloud, and finish with a quick demo of SSH tunneling in action.
SSH Tunnel Basics
SSH tunnel is a mechanism for securely exposing a service, such as a database, located on a private network, to another network, such as the Internet. A bastion host runs the Secure Shell (SSH) server; the bastion host is typically accessible from the outside for SSH only, running no other services. The bastion host in turn is allowed to access a limited set of services on the private network.
Here’s a simple example – the bastion host is located in a DMZ, between two firewalls. Clients on the Internet can access the bastion host via SSH on port 22; all other ports are blocked by the outer firewall. The inner firewall allows traffic to one or more internal services, such as a database, via a limited set of ports. There is no direct access from the Internet to the private network.
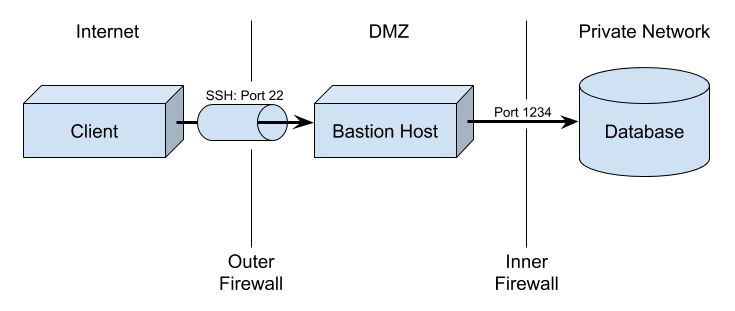
The SSH server on the bastion host must be configured with each client’s SSH public key. The public key is used to authenticate access to the SSH service; only clients with the corresponding private key can set up an SSH Tunnel.
To access the database, then, the client first sets up an SSH tunnel to the bastion host, using its private key to authenticate to the SSH server. The SSH tunnel listens on a local port at the client machine, and a client app can then connect to that local port as if it were accessing the database directly. The SSH tunnel encrypts the traffic as it crosses the Internet, and the SSH server acts as a proxy, forwarding traffic to the database.
SSH Tunnel and StreamSets Cloud
Users wishing to configure SSH tunnel in a data pipeline will need the SSH tunnel’s host, port (if it differs from the default of 22), username and, optionally, host fingerprint. The host fingerprint allows StreamSets Cloud to authenticate the SSH server; it may be left blank, in which case StreamSets Cloud will establish the connection without verifying the SSH server. Note that the fingerprint must be generated according to a particular format – see the StreamSets Cloud documentation for details.
With this in hand, a user can configure their data pipeline. In the relevant pipeline stage, they will select the ‘SSH Tunnel’ tab and enable ‘Use SSH Tunneling’. The user will enter the above parameters, clicking ‘Show Advanced Options’ if necessary to set the port and/or host fingerprint, and download the SSH public key.
You, as the network administrator, will need to install the SSH public key onto the SSH server so that StreamSets Cloud is allowed access. You will also need to allow inbound connections from the StreamSets Cloud IP addresses, as detailed in the documentation. StreamSets Cloud provides a single public SSH key that is unique per account. All pipeline stages in that account use the same public key to connect to the SSH server.
With that done, the user can proceed to configure the pipeline stage with the connection string, query, credentials etc, use preview to verify the connection and see the first few rows of data, and run the pipeline to read data from, or write data to, the database.
SSH Tunneling in Action
I was keen to try out SSH tunneling with the minimum number of steps, and I realized that I could allow StreamSets Cloud to query the PostgreSQL database running on my laptop, at home. I’ll walk through the steps I took to achieve this, so you can play along at home. Note that a real enterprise data center will have very different practices and procedures!
My network architecture is a little simpler than the example above – I don’t have a DMZ, and I simply run the SSH server and database on my laptop:
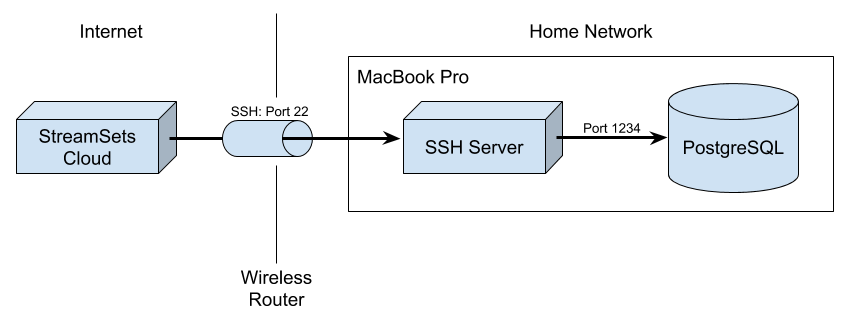
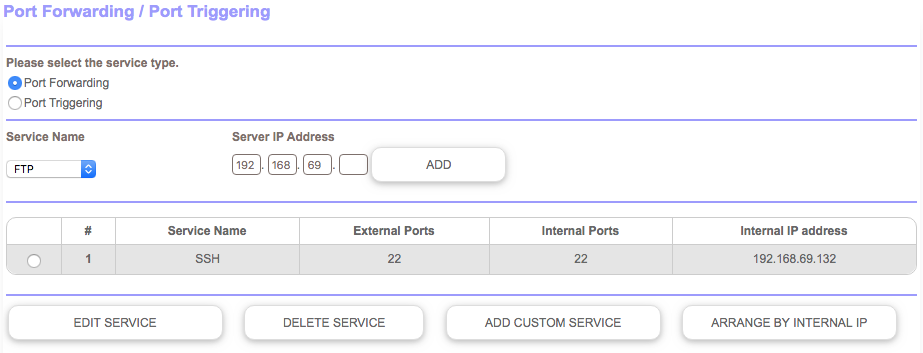
My first step was to configure my router to forward traffic on port 22 to my laptop:
I then created a simple pipeline with a PostgreSQL Query Consumer:
Following the StreamSets Cloud documentation for SSH tunnel, I generated the host fingerprint on my laptop:
pat@pat-macbookpro ~ % echo "$(ssh-keyscan localhost 2>/dev/null | ssh-keygen -l -f - | cut -d ' ' -f 2)" | paste -sd "," - SHA256:20Be0xJMrtkbuWIonS4Ct17Clvrkkefd6PMAbfaXOyc,SHA256:KGVrkRiM9IT0I6fB7JnAcHSUryXeDcCKC5Q0xxEKmUo,SHA256:3DA7J2SIZ96DsxaE0fzuktFfR5FA0uCSrBu+7oWWbyY
Now I could fill out the SSH Tunnel tab on the PostgreSQL origin. Note that I enabled ‘Show Advanced Options’ to configure the host fingerprint.
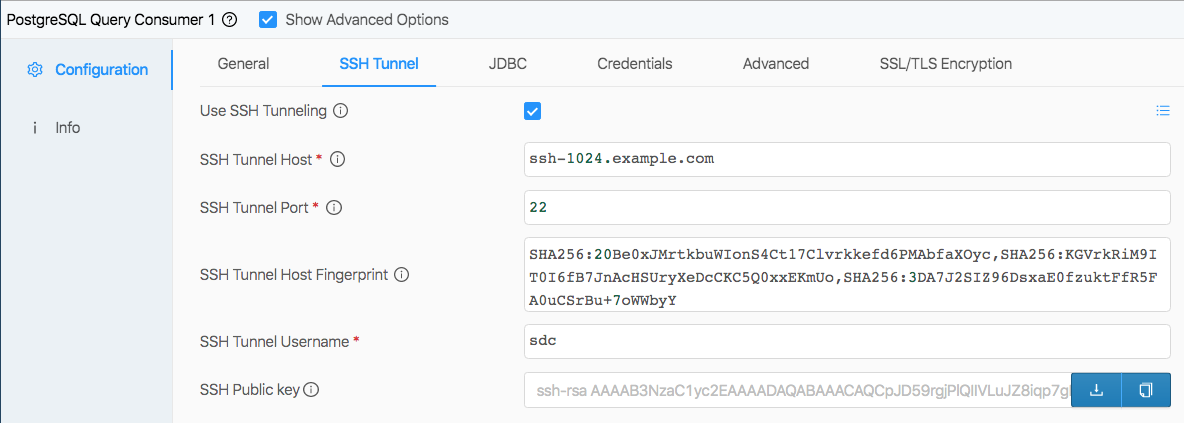
Looking at each configuration property in turn:
- Use SSH Tunneling is checked, revealing the remainder of the properties
- SSH Tunnel Host is set to my router’s external IP address. You can check your router configuration or simply google what’s my ip to discover this.
- SSH Tunnel Port is left with the default SSH port number, 22.
- SSH Tunnel Host Fingerprint has the fingerprint value I generated on my laptop.
- SSH Tunnel Username has my username on my laptop
Next I downloaded the SSH public key file to my laptop and installed it. Again, I following the StreamSets Cloud documentation:
pat@pat-macbookpro ~ % ssh-copy-id -f -i ~/Downloads/streamsetscloud_tunnelkey.pub pat@localhost /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/Users/pat/Downloads/streamsetscloud_tunnelkey.pub" Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'pat@localhost'" and check to make sure that only the key(s) you wanted were added.
Before I could test it out, I needed to configure the PostgreSQL Query Consumer with a JDBC connection string, query etc:

I configured a simple incremental query to retrieve rows based on a primary key, so I could add data as the pipeline was running and see it being processed in near real-time.
Note that the hostname in the connection string is internal to my home network. Remember, my laptop is not directly exposed to the Internet; the SSH server, running inside the local network, makes the connection, so the hostname need only be locally resolvable.
Without a doubt, my favorite StreamSets Cloud feature is preview. I can preview even a partial pipeline, comprising just an origin, to check its configuration and see the first few records from the data source. Previewing my embryonic pipeline showed that StreamSets Cloud could indeed read data from my laptop, located on my home network, via SSH tunnel:

Now that I can read data successfully, I need to send it somewhere! For the purposes of this demo, I selected Amazon Kinesis.
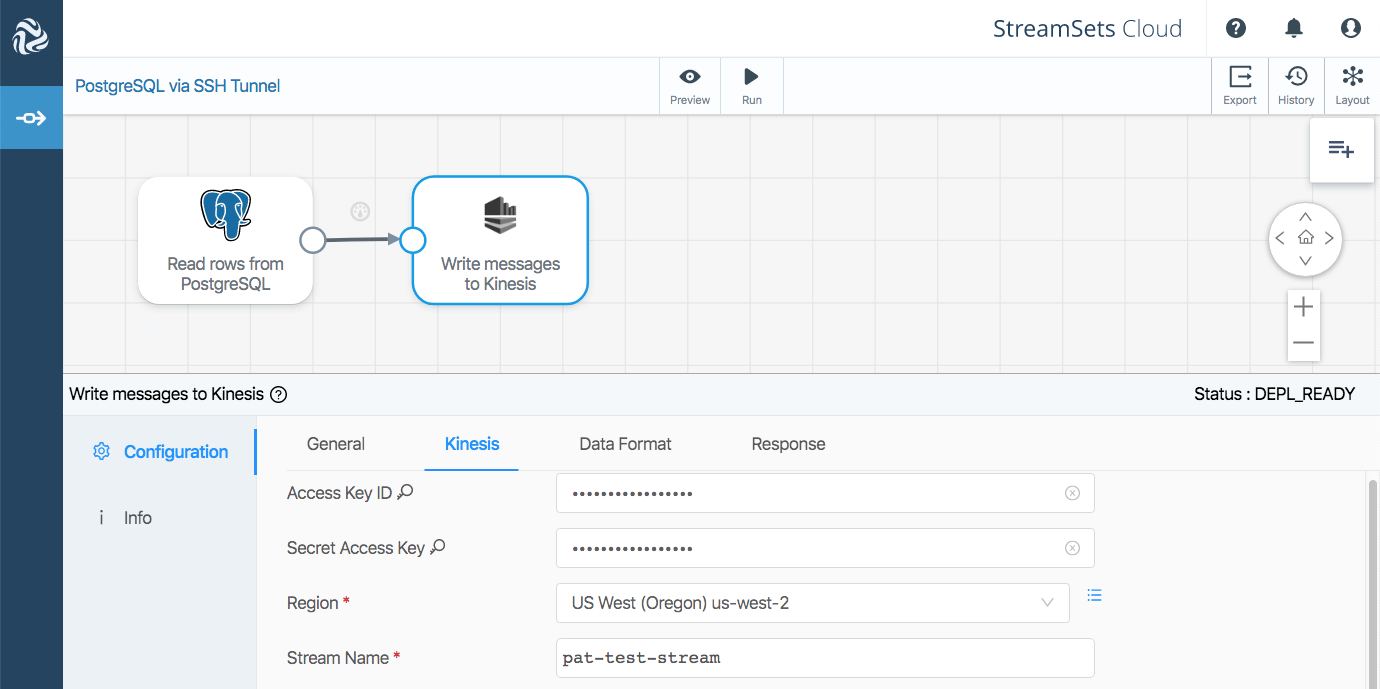
StreamSets Cloud’s Kinesis Producer sends messages to a Kinesis stream, and I can easily run a command-line tool to consume and display messages to verify that the pipeline is operating correctly. The blog entry Creating Dataflow Pipelines with Amazon Kinesis explains how to build data pipelines to send data to and receive data from Kinesis Data Streams in the context of StreamSets Data Collector; StreamSets Cloud’s Kinesis stages work in exactly the same way.
I could now run the pipeline to see data being streamed from PostgreSQL to Kinesis:

Using the aws command line tool and a bit of shell magic to read the Kinesis stream:
pat@pat-macbookpro ~ % shard_iterator=$(aws kinesis get-shard-iterator --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON --stream-name pat-test-stream | jq -r .ShardIterator)
pat@pat-macbookpro ~ % while true; do
response=$(aws kinesis get-records --shard-iterator ${shard_iterator})
echo ${response} | \
jq -r '.Records[]|[.Data] | @tsv' |
while IFS=$'\t' read -r data; do
echo $data | \
openssl base64 -d -A | \
jq .
done
shard_iterator=$(echo ${response} | jq -r .NextShardIterator)
done
{
"id": 758,
"name": "Bob"
}
{
"id": 759,
"name": "Jim"
}
{
"id": 760,
"name": "William"
}
{
"id": 761,
"name": "Jane"
}
{
"id": 762,
"name": "Sarah"
}
{
"id": 763,
"name": "Kirti"
}
Success!
This short video shows the pipeline in action:
Conclusion
StreamSets Cloud can securely access cloud-based relational database services such as Amazon RDS, Google Cloud SQL and Azure’s databases directly, or on-premise databases such as PostgreSQL, MySQL, Oracle and SQL Server via an SSH tunnel. Start your free trial of StreamSets Cloud today!
The post Digging Deeper into StreamSets Cloud and SSH Tunnel appeared first on StreamSets.